CPUs, GPUs, NPUs, and TPUs: The Hardware Foundation of Modern AI
December 21, 2025
The explosive growth of artificial intelligence has been fueled not just by algorithmic innovation, but by a fundamental shift in how we think about computing hardware. The journey from CPUs to specialized accelerators represents one of the most important hardware transitions in modern computing. Understanding these processors and how to optimize for them has become essential knowledge for machine learning engineers, systems researchers, and anyone building AI applications at scale.
The Evolution: Why We Stopped Using Just CPUs
In the early days of deep learning, researchers trained neural networks on CPUs. It worked, but it was slow. A model that takes hours on a GPU might take days or weeks on a CPU. This wasn't a limitation of software engineering; it was fundamental to how these processors are architected.
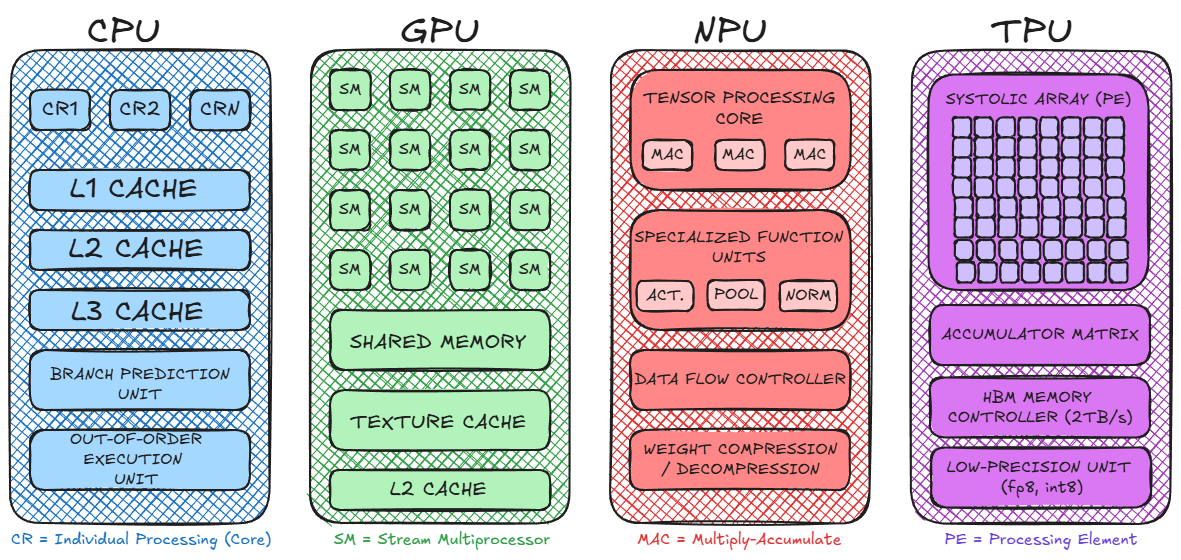
CPUs are optimized for sequential, general purpose workloads. They prioritize low latency and instruction level parallelism, with sophisticated branch prediction and out of order execution. They have large cache hierarchies and are built to handle complex control flow efficiently. This makes them excellent for database operations, web servers, and traditional applications.
But neural network computation is fundamentally different. Training and inference involve performing the same operation (matrix multiplication, convolution, activation functions) on massive amounts of data, often with straightforward control flow. This is a perfect match for data level parallelism, doing the same thing to different pieces of data simultaneously.
This mismatch is why GPUs, originally designed for rendering graphics, became the engine that powered the deep learning revolution.
GPUs: The Workhorse of Modern AI
Graphics processors excel at exactly what deep learning needs: massively parallel computation on large arrays of data. A modern GPU like the NVIDIA H100 contains over 14,000 CUDA cores, each capable of performing floating-point operations independently. This architecture enables processing millions of operations per second across different data elements.
GPUs became the default choice for AI workloads because they offered several critical advantages:
Raw Throughput: A high-end GPU delivers 50-100x the floating-point operations per second compared to a CPU for the same power envelope. For training large language models, this translates to the difference between waiting weeks versus days.
Memory Bandwidth: Neural networks shuffle enormous amounts of data. GPUs feature wide memory buses (with the H100 offering up to 3 TB/s bandwidth) that CPUs simply cannot match. This is crucial because in many operations, the bottleneck isn't computation, it's feeding data to the compute units fast enough.
However, GPUs come with trade offs. They consume significant power (an H100 draws up to 700W), require sophisticated cooling, and are overkill for some inference workloads. A language model might need powerful compute during training, but serving a single user query might not benefit from thousands of cores working in parallel.
NPUs: AI Processing for the Masses
Neural Processing Units represent a newer class of hardware designed specifically for neural network inference (though some are branching into training). Rather than being general accelerators like GPUs, NPUs are purpose built for the computational patterns in modern deep learning.
Companies like Qualcomm and Apple have integrated NPUs into smartphones and edge devices. Apple's Neural Engine in recent iPhones, for instance, can execute complex models locally, enabling on device processing for tasks like photo enhancement, transcription, and language understanding without sending data to the cloud.
Key characteristics of NPUs:
Energy Efficiency: NPUs are engineered to accomplish neural network computations with minimal power draw. An NPU might execute a model in milliwatts, where a GPU would use watts. This is critical for mobile and IoT devices where battery life is paramount.
Reduced Precision: Most NPUs operate efficiently on lower-precision arithmetic, int8 or even int4 quantization rather than float32. This saves memory, bandwidth, and compute while often maintaining acceptable accuracy for inference.
Specialization: Unlike GPUs (which remain relatively general accelerators), NPUs are specialized. They excel at dense matrix operations fundamental to neural networks but may struggle with workloads that don't fit this pattern. This specialization drives efficiency gains.
Deployment Context: NPUs are deployed where GPUs aren't practical, such as smartphones, IoT devices, edge servers, autonomous vehicles. They're enabling AI at the edge, reducing latency and improving privacy by processing data locally.
The emergence of capable NPUs has significant implications. Large language models are being optimized to run on mobile NPUs. Computer vision models operate continuously on edge devices. This shift is creating a computing hierarchy: data centers with GPUs/TPUs for training and heavy inference, regional servers with more modest acceleration, and billions of devices with lightweight NPUs handling user facing workloads.
TPUs: Google's Specialized Tensor Engines
While NVIDIA has dominated GPU acceleration for AI, Google took a different approach: building custom silicon from the ground up for tensor operations. Tensor Processing Units (TPUs) are application specific integrated circuits (ASICs) designed exclusively for machine learning workloads.
Unlike GPUs (which add neural network optimizations to graphics hardware), TPUs abandon GPU generality entirely. The tradeoff is striking:
Extreme Specialization: TPUs implement tensor operations directly in hardware. Operations that a GPU accomplishes through thousands of parallel threads, a TPU accomplishes through specialized datapaths. This reduces overhead and improves efficiency.
Efficiency: TPUs are remarkably efficient, delivering high throughput while consuming less power than comparable GPUs.
Reduced Precision by Design: Like NPUs, TPUs emphasize lower precision computation. Newer generations support a dedicated 8-bit floating-point format (fp8) that balances range and precision for neural networks.
Trade-offs: TPUs are less flexible than GPUs. A workload that doesn't fit the tensor computation model natively might be slower on TPU. GPU vendors like NVIDIA have worked hard to support broader workloads (scientific computing, graphics, simulation), while TPUs remain laser focused on ML.
The Heterogeneous Future
The future of AI hardware isn't about finding a single winning processor, it's about orchestrating diverse hardware effectively. A single ML system might use:
- GPUs in data centers for training
- TPUs in cloud infrastructure for dense inference
- NPUs on edge devices for latency-sensitive inference
- CPUs for preprocessing, control logic, and general computation
This heterogeneity creates both opportunities and challenges. A well designed system recognizes where different hardware excels and routes computation accordingly. This requires awareness of not just the hardware itself, but the software stacks, programming models, and optimization techniques for each.
The shift from CPUs to specialized accelerators—GPUs, NPUs, and TPUs has been one of the defining developments in modern computing. Each has emerged for good reason: GPUs because they unlocked massively parallel computation, NPUs because they bring that computation to the edge, and TPUs because extreme specialization beats generality for specific workloads.
Understanding these processors, their strengths, their limitations, and how to optimize for them is becoming a core competency for anyone serious about AI. The era of "just run it on a GPU" is giving way to a more sophisticated understanding of the hardware software co-design that makes AI systems actually work.
The next generation of ML engineers will be those who not only understand algorithms and frameworks, but also the hardware underneath—and how to optimize the whole system as a unified whole.
References
- IBM. "NPU vs GPU: Key differences." https://www.ibm.com/think/topics/npu-vs-gpu
- ACM Digital Library. https://doi.org/10.1145/3729215
- Emmanuel, F.C., Henry, O.N., & Chibuzo, O.B. "A Survey Comparing Specialized Hardware and Evolution in CPU, GPU AND TPU for Neural Network." Department of Computer Science, Clifford University; Department of Computer Science, Abia State University; Department of Computer Science, Gregory University Uturu.